
【skull-stripping入門】脳MRIから頭蓋骨を除去!Pythonで実装する手法を解説
脳MRI画像を用いた解析では、頭蓋骨や頭皮、髄膜などの非脳組織を除去し、脳実質のみを抽出する前処理が重要です。この処理は「スカルストリッピング(skull stripping)」または「脳抽出(brain extraction)」と呼ばれ、セグメンテーションや体積測定、機械学習モデルの入力作成など、多くの下流解析の基盤となります。 本記事では、公開データセット NFBS(The Neurofeedback Skull-stripped)を用い、PyTorch と UNet による深層学習ベースのスカルストリッピングを実装する流れを紹介します。データの取得・読み込みから、カスタムデータセットの構築、学習、推論までを順を追って解説します。
スカルストリッピングとは
スカルストリッピング(skull stripping)は、脳MRI画像から頭蓋骨、頭皮、髄膜、眼窩内容物などの非脳組織を除去し、脳実質(灰白質・白質・脳脊髄液)のみを残す画像処理です。
なぜ必要か
- 解析の精度向上:体積測定やセグメンテーションでは、脳組織のみを対象とするため、頭蓋骨などの強度が混ざると誤差の原因になります。
- 計算効率:関心領域を絞ることで、後続処理の負荷を軽減できます。
- 機械学習の入力:深層学習モデルでは、脳実質に特化した画像を入力とする場合が多く、前処理として必須となることがあります。
本記事では、深層学習(UNet)を用いたスカルストリッピングの実装に焦点を当てます。
準備:データの取得
本記事では Google Colaboratory 上での実行を想定しています。Skull-Stripping を行うためには、まず学習や検証に使用する脳MRIデータが必要です。公開されている NFBS Brain MRI データセット を利用します。
NFBS Skull-Stripped Repository(NFBS:The Neurofeedback Skull-stripped)は、Preprocessed Connectomes Project(PCP)が公開する医用画像データセットです。Enhanced Rockland Sample Neurofeedback Study の一環として収集された 125 件の T1 強調脳 MRI を収録し、各被験者ごとに構造 T1 画像、専門家による手動修正を経たスカルストリッピング済み画像、脳マスクの 3 種類を 1 mm³ 解像度の NIfTI 形式(.nii.gz)で提供しています。脳抽出やセグメンテーションの機械学習におけるゴールドスタンダードとして、研究・実験の現場で広く利用されています。
データの取得と解凍
Colab のセルで以下のコマンドを実行すると、wget でデータをダウンロードし、tar で解凍できます。1行目で NFBS_Dataset.tar.gz を /content に取得し、2行目で解凍します。解凍後には /content/NFBS_Dataset 以下に被験者ごとのフォルダ(A で始まる名前)が生成され、各フォルダに T1 画像と脳マスクが格納されています。
# NFBS データセットの取得と解凍(Google Colaboratory)
!wget https://fcp-indi.s3.amazonaws.com/data/Projects/RocklandSample/NFBS_Dataset.tar.gz
!tar -zxvf /content/NFBS_Dataset.tar.gz環境構築とライブラリのインポート
データ取得後、必要なライブラリをインポートします。nibabel で NIfTI 形式の医用画像を読み込み、PyTorch でモデル・データローダーを構築し、scikit-learn でデータ分割、matplotlib で可視化、tqdm で進捗表示を行います。
import os
import glob
import nibabel as nib
import numpy as np
from tqdm import tqdm
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import torch.nn.functional as F
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
print("全てのライブラリのインポートが完了しました!")全てのライブラリのインポートが完了しました!NFBSデータセットの読み込み
NFBS データセットは被験者単位でフォルダが分かれており、各フォルダには T1 強調 MRI 画像(*_T1w.nii.gz)と脳マスク画像(*_T1w_brainmask.nii.gz)のペアが格納されています。T1 画像は頭部全体の生データ、脳マスクは頭蓋骨などを除去した脳領域のみを示す二値画像です。このペアを「入力」と「正解ラベル」として教師あり学習に利用します。
nibabel で NIfTI ファイルを読み込み、as_closest_canonical で画像の向きを標準化し、squeeze_image で余分な次元を削除してから NumPy 配列に変換します。計算資源を考慮し、最大 50 件まで読み込み、train_test_split で 8:2 の割合に訓練・検証に分割します。同じデータを学習と評価の両方に使うと過学習の評価が難しくなるため、検証データで汎化性能を確認できるようにします。
# NFBS データセットのルート
data_dir = "/content/NFBS_Dataset"
# 画像とマスクを格納するリスト
voxels = [] # MRI画像
labels = [] # マスク画像
# 最大50個のデータのみ読み込み
max_samples = 50
sample_count = 0
# 各被験者フォルダをループ
subject_dirs = sorted(glob.glob(os.path.join(data_dir, "A*")))
pbar = tqdm(subject_dirs, total=min(len(subject_dirs), max_samples), desc="読み込み中")
for subject_dir in pbar:
if sample_count >= max_samples:
break
# MRI とマスクのファイルパスを取得
mri_files = glob.glob(os.path.join(subject_dir, "*_T1w.nii.gz"))
mask_files = glob.glob(os.path.join(subject_dir, "*_T1w_brainmask.nii.gz"))
if not mri_files or not mask_files:
print(f"ファイルが見つかりません: {subject_dir}")
continue
mri_path = mri_files[0]
mask_path = mask_files[0]
# NIfTI を読み込み → numpy 配列に変換
mri_img_obj = nib.squeeze_image(nib.as_closest_canonical(nib.load(mri_path)))
mask_img_obj = nib.squeeze_image(nib.as_closest_canonical(nib.load(mask_path)))
# データ部分を取得してnumpy配列に変換
mri_data = mri_img_obj.get_fdata().astype("float32")
mask_data = mask_img_obj.get_fdata().astype("int16")
# リストに追加
voxels.append(mri_data)
labels.append(mask_data)
sample_count += 1
pbar.set_postfix({"読み込み済み": sample_count})
print(f"読み込み完了: {len(voxels)} 件")
# 訓練・検証分割(8:2)
train_voxels, val_voxels, train_labels, val_labels = train_test_split(voxels, labels, test_size=0.2, random_state=42)
print(f"訓練データ: {len(train_voxels)} 件, 検証データ: {len(val_voxels)} 件")読み込み中: 100%|██████████| 50/50 [00:29<00:00, 1.67it/s, 読み込み済み=50]
読み込み完了: 50 件
訓練データ: 40 件, 検証データ: 10 件データの可視化(確認)
MRI データを読み込んだら、まず「本当に正しく読み込めているか」を確かめることが最初に行うべき作業です。医用画像は三次元のボリュームデータであり、単に配列の shape(形状)を確認するだけでは、脳の構造がきちんと反映されているのか、マスクが対応しているのかを判断することはできません。そのため、可視化による目視確認が欠かせません。
確認方法としては、Z 軸方向の中央スライスを取り出すのがわかりやすいアプローチです。MRI は縦・横・奥行きの三方向にスライスが存在しますが、その中央部分を選ぶことで代表的な断面を観察できます。このスライスを用い、以下の三種類を並べて可視化すると、入力とラベルの関係が直感的に理解しやすくなります。ひとつ目は元の T1 強調 MRI 画像で、脳だけでなく頭蓋骨を含んだオリジナルの状態です。ふたつ目は、その MRI にマスクを適用し脳組織のみを抽出した画像です。三つ目がマスク画像そのもので、白が脳、黒が非脳組織を示すラベル画像です。
さらに、こうした可視化を一人分だけでなく複数の患者について横並びに表示すると、データのばらつきやマスクの位置のずれがないかを効率的にチェックできます。axial(軸位)、sagittal(矢状)、coronal(冠状)の 3 断面で表示することで、読み込んだ配列に異常がないか、ファイルが壊れていないかを一目で確認できます。
こうした目視確認は「前処理や学習を進めてよいかどうか」を判断する品質チェックでもあります。この段階でマスクがオリジナル画像とうまく重なっていなければ、その後どれだけ高度なモデルを学習させても正しい結果は得られません。
表示のポイント
- imshow:画像を表示する。cmap='gray' でグレースケール表示、axis('off') で軸を非表示にし、画像だけを見やすくする。
- **`mri_slice * (mask_slice > 0)`**:`mask_slice > 0` でマスクの非ゼロ部分(脳領域)を True にし、乗算で MRI に適用すると脳以外は 0 になり、脳領域だけが表示される。
import matplotlib.pyplot as plt
import numpy as np
def visualize_slices_horizontal(voxels, labels, view='axial', n_patients=10):
"""
患者を横並びで可視化(3行×n列)
view: 'axial', 'sagittal', 'coronal'
"""
n_patients = min(n_patients, len(voxels))
n_rows, n_cols = 3, n_patients
def fix_orientation(image_slice):
if view == 'axial':
return np.rot90(image_slice, k=3)
elif view == 'sagittal':
return np.fliplr(np.rot90(image_slice, k=1))
elif view == 'coronal':
return np.rot90(image_slice, k=1)
return image_slice
slice_idx = []
for v in voxels[:n_patients]:
if view == 'axial':
target_slice = min(165, v.shape[2] - 1)
slice_idx.append(target_slice)
elif view == 'sagittal':
slice_idx.append(v.shape[0] // 2)
elif view == 'coronal':
slice_idx.append(v.shape[1] // 2)
fig, axes = plt.subplots(n_rows, n_cols, figsize=(1.5 * n_cols, 6))
fig.suptitle(f'{view.capitalize()} View', fontsize=16, y=0.95)
for col in range(n_patients):
if view == 'axial':
mri_slice = fix_orientation(voxels[col][:, :, slice_idx[col]])
mask_slice = fix_orientation(labels[col][:, :, slice_idx[col]])
elif view == 'sagittal':
mri_slice = fix_orientation(voxels[col][slice_idx[col], :, :])
mask_slice = fix_orientation(labels[col][slice_idx[col], :, :])
else:
mri_slice = fix_orientation(voxels[col][:, slice_idx[col], :])
mask_slice = fix_orientation(labels[col][:, slice_idx[col], :])
axes[0, col].imshow(mri_slice, cmap='gray')
axes[0, col].axis('off')
axes[0, col].set_title(f"Sub {col+1}", fontsize=10)
axes[1, col].imshow(mask_slice, cmap='gray')
axes[1, col].axis('off')
axes[2, col].imshow(mri_slice * (mask_slice > 0), cmap='gray')
axes[2, col].axis('off')
plt.subplots_adjust(wspace=0.05, hspace=0.05)
plt.show()
visualize_slices_horizontal(voxels, labels, view='axial', n_patients=10)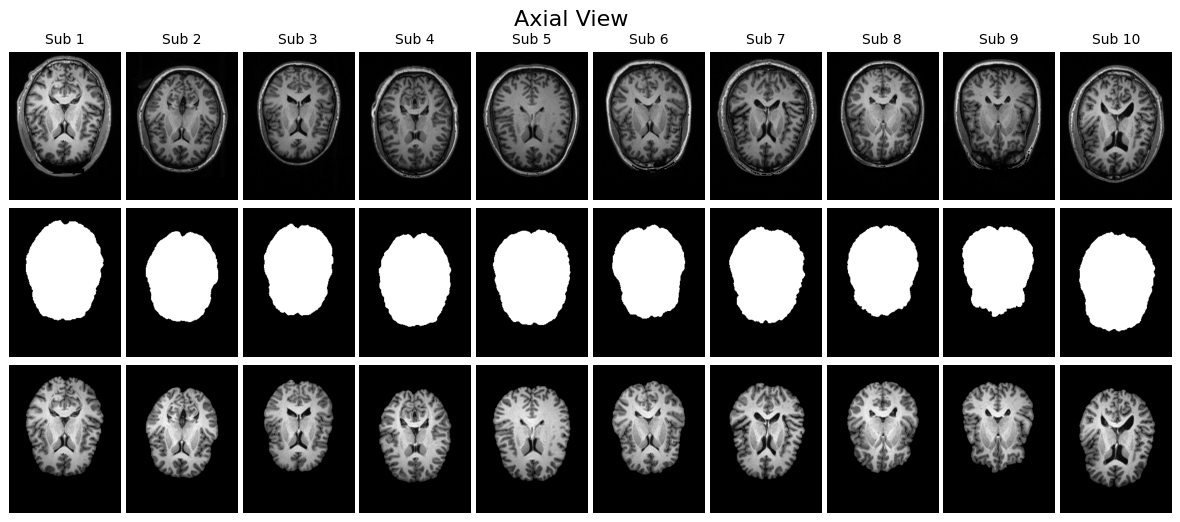
visualize_slices_horizontal(voxels, labels, view='sagittal', n_patients=10)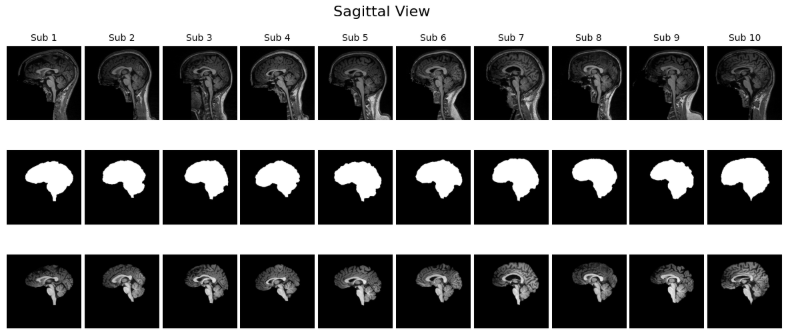
visualize_slices_horizontal(voxels, labels, view='coronal', n_patients=10)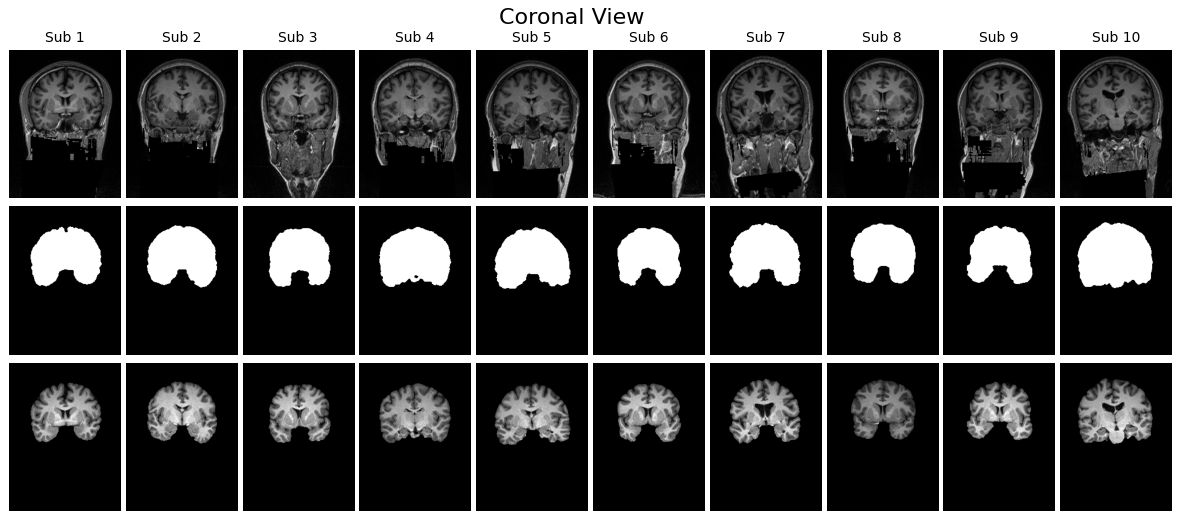
カスタムデータセットの構築
深層学習で医用画像を扱う際には、NIfTI 形式で保存された三次元の MRI ボリュームをそのままモデルに入力することはできません。そこで PyTorch の学習パイプラインに適した形に変換するため、カスタムデータセットクラスを定義します。PyTorch では torch.utils.data.Dataset を継承して自作クラスを作成するのが一般的で、これにより DataLoader と組み合わせてミニバッチ処理やシャッフル、並列読み込みを行えるようになります。
NFBS データセットは三次元ボリュームですが、今回は 3D-CNN ではなく 2D-CNN を用いるため、各被験者の T1w 画像を Z 軸方向にスライスして二次元画像に変換します。同じ位置でマスク画像も切り出すことで、MRI とマスクの対応がとれたペアが得られます。この方法により、一人の被験者から数百枚の学習サンプルが生成され、データ数を増やす効果も期待できます。
切り出したスライスには正規化を行います。MRI 画像は撮影条件によって明度やコントラストが異なるため、そのままでは学習が不安定になりやすいからです。画素値を 0〜1 の範囲に正規化したうえで PyTorch のテンソルに変換し、チャンネル次元を追加することでネットワークに入力できる形に整えます。一方、マスク画像は脳領域を 1、非脳領域を 0 とする二値ラベルとして扱います。
このようにして構築したカスタムデータセットを用いることで、「MRI スライスを入力すると、対応する脳マスクを出力する」という変換を学習する準備が整います。
import torch
import numpy as np
from torch.utils.data import Dataset
# カスタムデータセット(2Dスライス用)
class SkullStrippingDataset(Dataset):
def __init__(self, voxels, labels):
self.slices = []
self.masks = []
# 全てのボリュームから2Dスライスを抽出(Axial方向 = 3軸目)
for vol, mask in zip(voxels, labels):
for z in range(vol.shape[2]):
slice_2d = vol[:, :, z]
mask_2d = mask[:, :, z]
# 空のスライスはスキップ
if np.sum(slice_2d) > 0:
self.slices.append(slice_2d)
self.masks.append(mask_2d)
print(f"総スライス数: {len(self.slices)}")
def __len__(self):
return len(self.slices)
def __getitem__(self, idx):
slice_2d = self.slices[idx]
mask_2d = self.masks[idx]
# Min-Max正規化
slice_min = slice_2d.min()
slice_max = slice_2d.max()
if slice_max > slice_min:
slice_2d = (slice_2d - slice_min) / (slice_max - slice_min)
# マスクを0-1にクリップ
mask_2d = np.clip(mask_2d, 0, 1)
# テンソルに変換(チャンネル次元を追加)
slice_2d = torch.FloatTensor(slice_2d).unsqueeze(0) # (1, H, W)
mask_2d = torch.FloatTensor(mask_2d).unsqueeze(0) # (1, H, W)
return slice_2d, mask_2dUNetモデルの実装
医用画像のセグメンテーションにおいて、最も広く利用されているモデルのひとつが UNet です。本研究でも、このアーキテクチャを実装して利用しました。
UNet は、入力画像から特徴を抽出するエンコーダ部、抽出された情報をもとに空間的な解像度を回復するデコーダ部、そしてエンコーダの中間特徴をデコーダに橋渡しするスキップ接続の三要素から構成されます。この設計により、局所的な詳細情報と大域的な文脈情報の両方を効果的に活用できる点が大きな特徴です。
今回の実装では、PyTorch を用いてクラスとして UNet を定義しました。エンコーダでは、畳み込み層と正規化層、活性化関数を組み合わせたブロックを重ね、入力から徐々に抽象度の高い特徴を抽出していきます。ボトルネック部分で最も圧縮された表現を得た後、デコーダでは転置畳み込みにより空間解像度を段階的に回復しつつ、エンコーダからの対応する特徴マップを結合することで、失われがちな位置情報を補完します。最終的な出力は 1×1 の畳み込み層を通して、入力スライスごとにマスク画像を推定する形となっています。
学習環境は GPU が利用可能であれば CUDA を優先的に使用する設定とし、効率的な計算を実現しています。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
# UNetモデル
class UNet(nn.Module):
def __init__(self, in_channels=1, out_channels=1):
super(UNet, self).__init__()
# エンコーダ
self.enc1 = self.conv_block(in_channels, 64)
self.enc2 = self.conv_block(64, 128)
self.enc3 = self.conv_block(128, 256)
self.enc4 = self.conv_block(256, 512)
# ボトルネック
self.bottleneck = self.conv_block(512, 1024)
# デコーダ
self.up4 = nn.ConvTranspose2d(1024, 512, 2, stride=2)
self.dec4 = self.conv_block(1024, 512)
self.up3 = nn.ConvTranspose2d(512, 256, 2, stride=2)
self.dec3 = self.conv_block(512, 256)
self.up2 = nn.ConvTranspose2d(256, 128, 2, stride=2)
self.dec2 = self.conv_block(256, 128)
self.up1 = nn.ConvTranspose2d(128, 64, 2, stride=2)
self.dec1 = self.conv_block(128, 64)
# 出力層
self.out = nn.Conv2d(64, out_channels, 1)
def conv_block(self, in_ch, out_ch):
return nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
def forward(self, x):
# エンコード
e1 = self.enc1(x)
e2 = self.enc2(F.max_pool2d(e1, 2))
e3 = self.enc3(F.max_pool2d(e2, 2))
e4 = self.enc4(F.max_pool2d(e3, 2))
# ボトルネック
b = self.bottleneck(F.max_pool2d(e4, 2))
# デコード
d4 = self.up4(b)
d4 = torch.cat([d4, e4], dim=1)
d4 = self.dec4(d4)
d3 = self.up3(d4)
d3 = torch.cat([d3, e3], dim=1)
d3 = self.dec3(d3)
d2 = self.up2(d3)
d2 = torch.cat([d2, e2], dim=1)
d2 = self.dec2(d2)
d1 = self.up1(d2)
d1 = torch.cat([d1, e1], dim=1)
d1 = self.dec1(d1)
# 出力
out = self.out(d1)
return out
# デバイス設定
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用デバイス: {device}")
# データセットとデータローダーの作成
train_dataset = SkullStrippingDataset(train_voxels, train_labels)
val_dataset = SkullStrippingDataset(val_voxels, val_labels)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=False)
print(f"訓練スライス数: {len(train_dataset)}, 検証スライス数: {len(val_dataset)}")使用デバイス: cuda
総スライス数: 10200
総スライス数: 2550
訓練スライス数: 10200, 検証スライス数: 2550学習フェーズ
学習フェーズでは、モデルの予測結果と正解マスクとの誤差を測るために BCEWithLogitsLoss を用いました。これは二値分類に広く利用される損失関数であり、本研究のように「脳であるか否か」を画素単位で判別するタスクに適しています。最適化手法には計算効率と収束の安定性に優れた Adam を採用しました。これにより、勾配の更新が自動的に調整され、比較的少ないエポックでも学習が進みやすくなります。
学習の流れとしては、まず訓練データを用いてモデルを更新し、各エポックの終わりに検証データで性能を確認するというサイクルを繰り返します。これにより、単に訓練データへの当てはまりを見るだけでなく、未知のデータに対してもモデルがどの程度汎化できているかを同時に評価できます。訓練損失と検証損失を並行して追跡することで、過学習の兆候を早期に検出できる点も重要です。
さらに、学習の進行をより直感的に把握するために、エポックごとの損失の推移をグラフとして可視化しました。これにより、学習が安定して進んでいるか、あるいは停滞や発散が起きていないかを一目で確認することができます。
最後に、学習を終えたモデルは保存するようにしました。これにより、再学習の手間を省きつつ、異なる環境からでも同じモデルを再利用できる体制を整えています。
import torch.optim as optim
from tqdm import tqdm
import matplotlib.pyplot as plt
# モデル、損失関数、オプティマイザーの設定
model = UNet().to(device)
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 学習ループ
num_epochs = 10
train_losses = []
val_losses = []
print("学習開始...")
for epoch in range(num_epochs):
# 訓練フェーズ
model.train()
train_loss = 0.0
for batch_idx, (data, target) in enumerate(tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}")):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.item()
# 検証フェーズ
model.eval()
val_loss = 0.0
with torch.no_grad():
for data, target in val_loader:
data, target = data.to(device), target.to(device)
output = model(data)
val_loss += criterion(output, target).item()
# 平均損失を計算
train_loss = train_loss / len(train_loader)
val_loss = val_loss / len(val_loader)
train_losses.append(train_loss)
val_losses.append(val_loss)
print(f"Epoch {epoch+1}/{num_epochs}: Train Loss: {train_loss:.4f}, Val Loss: {val_loss:.4f}")
print("学習完了!")
# モデルの保存
torch.save(model.state_dict(), '/content/NFBS_Dataset/skull_stripping_model.pth')
print("モデルを保存しました: skull_stripping_model.pth")
# 損失の可視化
plt.figure(figsize=(10, 5))
plt.plot(range(1, num_epochs+1), train_losses, 'b-', label='Training Loss')
plt.plot(range(1, num_epochs+1), val_losses, 'r-', label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.grid(True)
plt.show()学習開始...
Epoch 1/10: 100%|██████████| 1275/1275 [07:37<00:00, 2.79it/s]
Epoch 1/10: Train Loss: 0.0491, Val Loss: 0.0188
Epoch 2/10: 100%|██████████| 1275/1275 [07:44<00:00, 2.75it/s]
Epoch 2/10: Train Loss: 0.0152, Val Loss: 0.0204
Epoch 3/10: 100%|██████████| 1275/1275 [07:44<00:00, 2.75it/s]
Epoch 3/10: Train Loss: 0.0115, Val Loss: 0.0117
Epoch 4/10: 100%|██████████| 1275/1275 [07:44<00:00, 2.75it/s]
Epoch 4/10: Train Loss: 0.0089, Val Loss: 0.0111
Epoch 5/10: 100%|██████████| 1275/1275 [07:44<00:00, 2.75it/s]
Epoch 5/10: Train Loss: 0.0077, Val Loss: 0.0724
Epoch 6/10: 100%|██████████| 1275/1275 [07:44<00:00, 2.75it/s]
Epoch 6/10: Train Loss: 0.0096, Val Loss: 0.0085
Epoch 7/10: 100%|██████████| 1275/1275 [07:44<00:00, 2.75it/s]
Epoch 7/10: Train Loss: 0.0068, Val Loss: 0.0070
Epoch 8/10: 100%|██████████| 1275/1275 [07:44<00:00, 2.75it/s]
Epoch 8/10: Train Loss: 0.0066, Val Loss: 0.0069
Epoch 9/10: 100%|██████████| 1275/1275 [07:44<00:00, 2.75it/s]
Epoch 9/10: Train Loss: 0.0073, Val Loss: 0.0073
Epoch 10/10: 100%|██████████| 1275/1275 [07:44<00:00, 2.75it/s]
Epoch 10/10: Train Loss: 0.0076, Val Loss: 0.0067
学習完了!
モデルを保存しました: skull_stripping_model.pth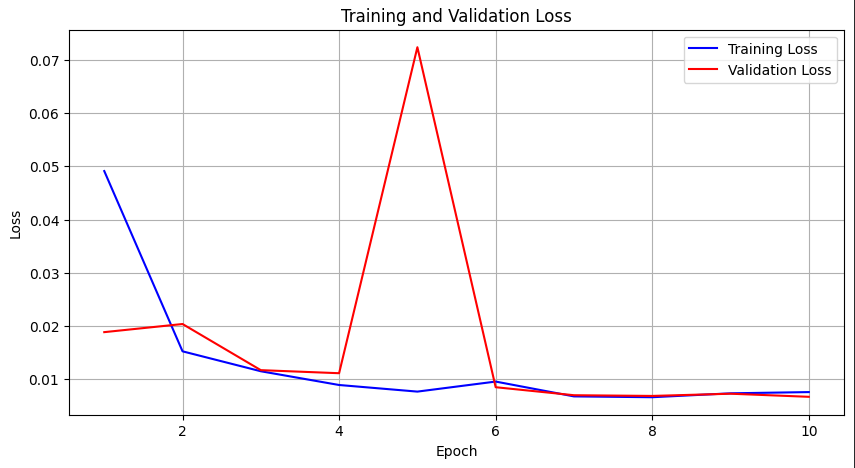
推論フェーズ(Inference)
推論フェーズでは、まず学習済みのモデルをロードし、新しい被験者の T1 強調 MRI 画像を入力として与えます。画像は三次元のボリュームデータであるため、学習時と同様に Z 軸方向に沿った二次元スライスへと分割し、それぞれをモデルに入力します。これにより、各スライスに対して脳領域である確率が画素単位で出力され、全体として三次元的な脳マスクを推定することが可能になります。
モデルの出力は連続値の確率分布であり、そのままでは利用が難しいため、一般的な二値化処理を行います。具体的には、確率が 0.5 以上であれば脳領域、未満であれば背景とみなし、最終的に 0 と 1 からなるバイナリマスクを作成します。この閾値処理は単純ながら実用的であり、学習時に用いた損失関数とも整合しています。
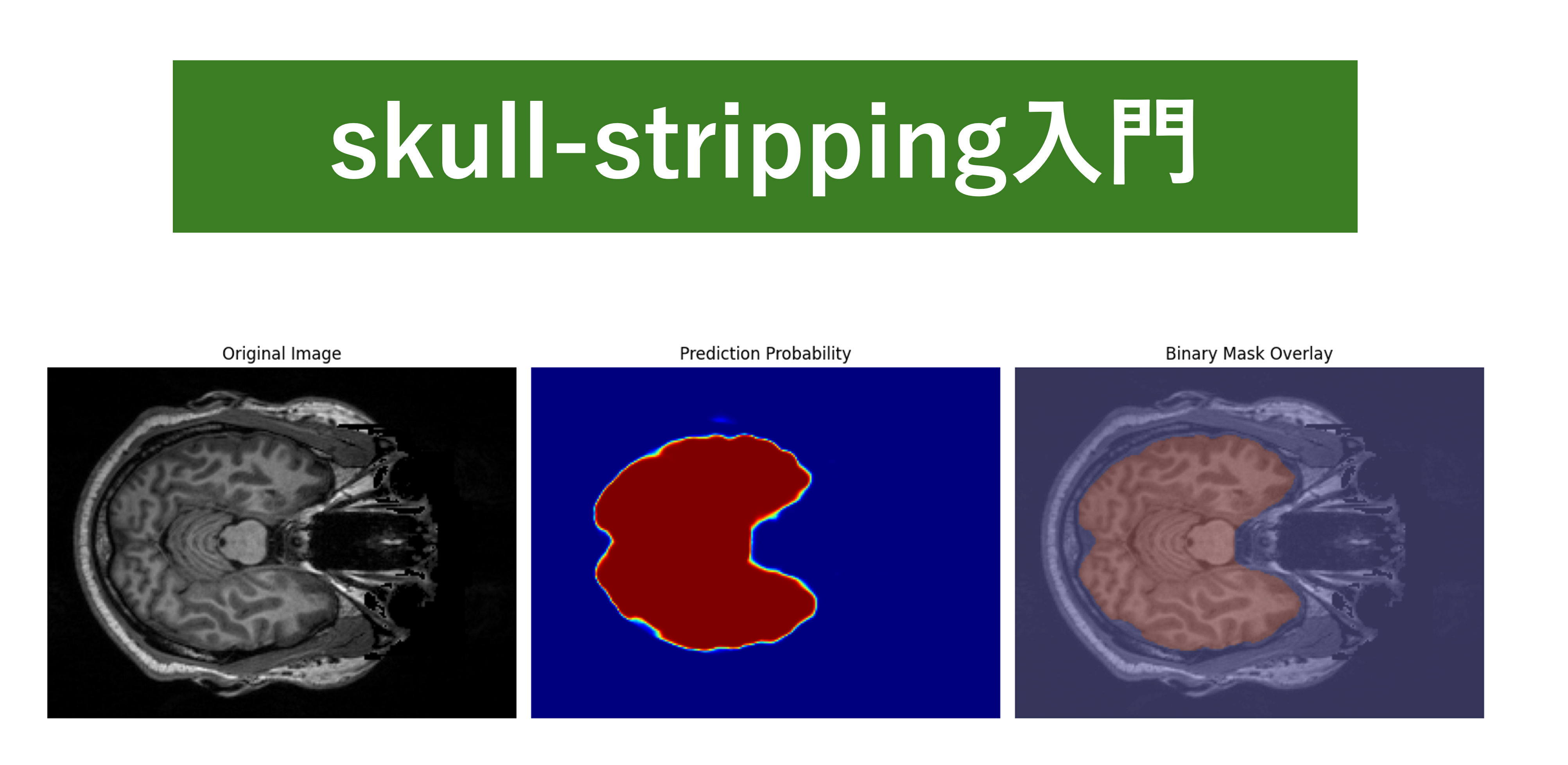
得られた予測結果は、可視化によって直感的に確認できるようにします。具体的には、元の T1w 画像に加え、モデルが出力した確率マップ、そして予測マスクをオーバーレイした画像を並べて表示します。これにより、推定された脳領域がどの程度正確に実際の脳構造と一致しているのかを、研究者自身の目で検証することができます。
最後に、推論によって得られたマスクは NIfTI 形式として保存します。これにより、他の研究者や医療用ソフトウェアと容易に共有・利用できる形となり、再利用性や臨床応用への橋渡しが可能になります。
# ========== 推論用の関数 ==========
def load_trained_model(model_path, device):
"""学習済みモデルを読み込む"""
model = UNet().to(device)
model.load_state_dict(torch.load(model_path, map_location=device))
model.eval()
print(f"モデル読み込み完了: {model_path}")
return model
def predict_single_volume(model, volume, device, batch_size=8):
"""
3D画像からskull-stripping予測を実行
volume: 3D numpy配列 (H, W, D)
"""
H, W, D = volume.shape
predicted_mask = np.zeros_like(volume, dtype=np.float32)
slices = []
slice_indices = []
for z in range(D):
slice_2d = volume[:, :, z].astype(np.float32)
# Min-Max正規化
slice_min = slice_2d.min()
slice_max = slice_2d.max()
if slice_max > slice_min:
slice_2d = (slice_2d - slice_min) / (slice_max - slice_min)
slice_tensor = torch.FloatTensor(slice_2d).unsqueeze(0).unsqueeze(0) # (1, 1, H, W)
slices.append(slice_tensor)
slice_indices.append(z)
# バッチ処理で推論
with torch.no_grad():
for i in range(0, len(slices), batch_size):
batch_slices = slices[i:i+batch_size]
batch_indices = slice_indices[i:i+batch_size]
batch_tensor = torch.cat(batch_slices, dim=0).to(device)
outputs = model(batch_tensor)
predictions = torch.sigmoid(outputs)
for j, z_idx in enumerate(batch_indices):
predicted_mask[:, :, z_idx] = predictions[j, 0].cpu().numpy()
return predicted_mask
def apply_threshold(prediction, threshold=0.5):
"""予測結果に閾値を適用してバイナリマスクに変換"""
return (prediction > threshold).astype(np.uint8)
def visualize_results(original, prediction, binary_mask, slice_idx=None):
"""結果を可視化"""
if slice_idx is None:
slice_idx = original.shape[2] // 2
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
axes[0].imshow(original[:, :, slice_idx], cmap='gray')
axes[0].set_title('Original Image')
axes[0].axis('off')
axes[1].imshow(prediction[:, :, slice_idx], cmap='jet', vmin=0, vmax=1)
axes[1].set_title('Prediction Probability')
axes[1].axis('off')
axes[2].imshow(original[:, :, slice_idx], cmap='gray', alpha=0.7)
axes[2].imshow(binary_mask[:, :, slice_idx], cmap='jet', alpha=0.3)
axes[2].set_title('Binary Mask Overlay')
axes[2].axis('off')
plt.tight_layout()
plt.show()
def save_prediction(prediction, reference_nifti_path, output_path):
"""予測結果をNIfTIファイルとして保存"""
ref_img = nib.squeeze_image(nib.as_closest_canonical(nib.load(reference_nifti_path)))
pred_img = nib.Nifti1Image(prediction, ref_img.affine, ref_img.header)
nib.save(pred_img, output_path)
print(f"予測結果を保存しました: {output_path}")
# ========== 実際の使用例 ==========
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 1. 学習済みモデルの読み込み
model_path = '/content/drive/MyDrive/em/skull_stripping_model.pth'
model = load_trained_model(model_path, device)
# 2. テスト用画像の読み込み
test_image_path = "/content/drive/MyDrive/em/NFBS_Dataset/A00062288/sub-A00062288_ses-NFB3_T1w.nii.gz"
test_img = nib.squeeze_image(nib.as_closest_canonical(nib.load(test_image_path)))
test_volume = test_img.get_fdata().astype("float32")
print(f"テスト画像サイズ: {test_volume.shape}")
# 3. 推論実行
print("推論実行中...")
predicted_mask = predict_single_volume(model, test_volume, device, batch_size=4)
# 4. バイナリマスクに変換
binary_mask = apply_threshold(predicted_mask, threshold=0.5)
# 5. 結果の可視化
print("結果を可視化中...")
visualize_results(test_volume, predicted_mask, binary_mask)
# 6. 結果の保存
output_path = '/content/drive/MyDrive/em/predicted_brainmask.nii.gz'
save_prediction(binary_mask.astype(np.float32), test_image_path, output_path)
print("推論完了!")モデル読み込み完了: /content/drive/MyDrive/em/skull_stripping_model.pth
テスト画像サイズ: (192, 256, 256)
推論実行中...
結果を可視化中...
予測結果を保存しました: /content/drive/MyDrive/em/predicted_brainmask.nii.gz
推論完了!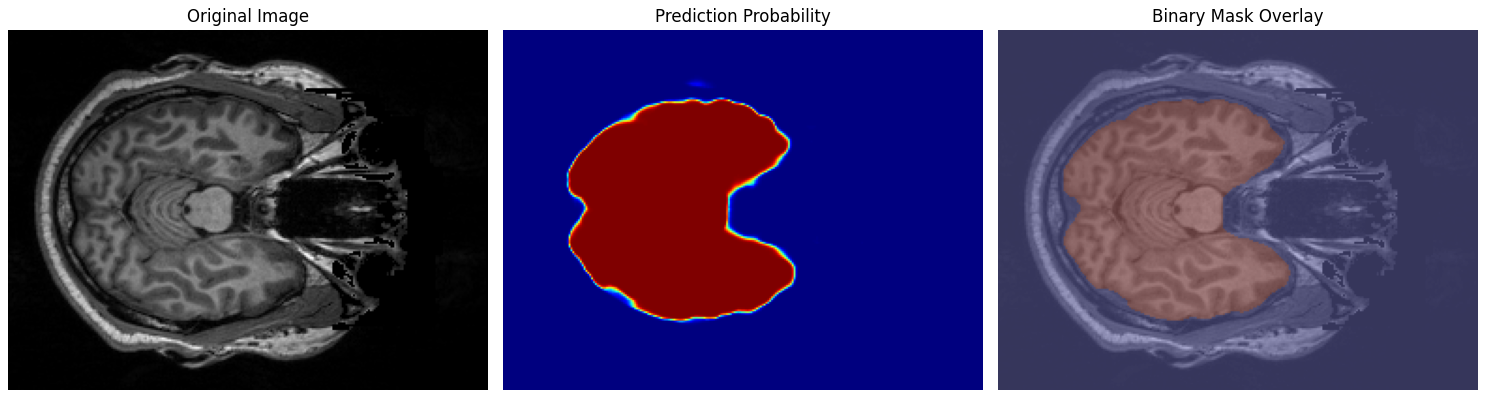
複数スライスの可視化(オプション)
推論の結果を確認する際には、一枚のスライスだけを可視化するよりも、連続した複数のスライスを並べて表示する方が有効です。特に脳 MRI のような三次元ボリュームデータでは、空間的な連続性が重要な意味を持ちます。中心付近のスライスをいくつか選び、元の画像と予測マスクを横に並べることで、モデルが隣接する断面に対しても一貫した推論を行えているかを直感的に確認できます。
このような可視化は、単に予測の正否を判断するだけでなく、モデルの安定性を評価する上でも役立ちます。もしあるスライスだけマスクがずれていたり、脳領域の形が不自然に途切れていた場合、それは学習データの偏りやモデルの汎化性能の不足を示す可能性があります。一方で、連続するスライスにおいて脳領域が滑らかに再現されていれば、モデルがボリューム全体の構造を捉えている証拠となります。
また、この方法は研究者自身が直感的に異常を見つけるための「品質保証」の手段としても機能します。数値評価指標では見落とされるような局所的なエラーも、複数スライスを俯瞰することで把握しやすくなります。そのため、推論の信頼性を高めるための補助的なステップとして、複数スライスの可視化は非常に有用です。
# ========== 複数スライスの可視化(オプション) ==========
def visualize_multiple_slices(original, prediction, binary_mask, num_slices=6):
"""複数のスライスを表示"""
D = original.shape[2]
slice_indices = np.linspace(D//4, 3*D//4, num_slices).astype(int)
fig, axes = plt.subplots(3, num_slices, figsize=(20, 12))
for i, slice_idx in enumerate(slice_indices):
# 元画像
axes[0, i].imshow(original[:, :, slice_idx], cmap='gray')
axes[0, i].set_title(f'Original (z={slice_idx})')
axes[0, i].axis('off')
# 予測確率
axes[1, i].imshow(prediction[:, :, slice_idx], cmap='jet', vmin=0, vmax=1)
axes[1, i].set_title(f'Prediction (z={slice_idx})')
axes[1, i].axis('off')
# オーバーレイ
axes[2, i].imshow(original[:, :, slice_idx], cmap='gray', alpha=0.7)
axes[2, i].imshow(binary_mask[:, :, slice_idx], cmap='jet', alpha=0.3)
axes[2, i].set_title(f'Overlay (z={slice_idx})')
axes[2, i].axis('off')
plt.tight_layout()
plt.show()
# 複数スライス表示
visualize_multiple_slices(test_volume, predicted_mask, binary_mask)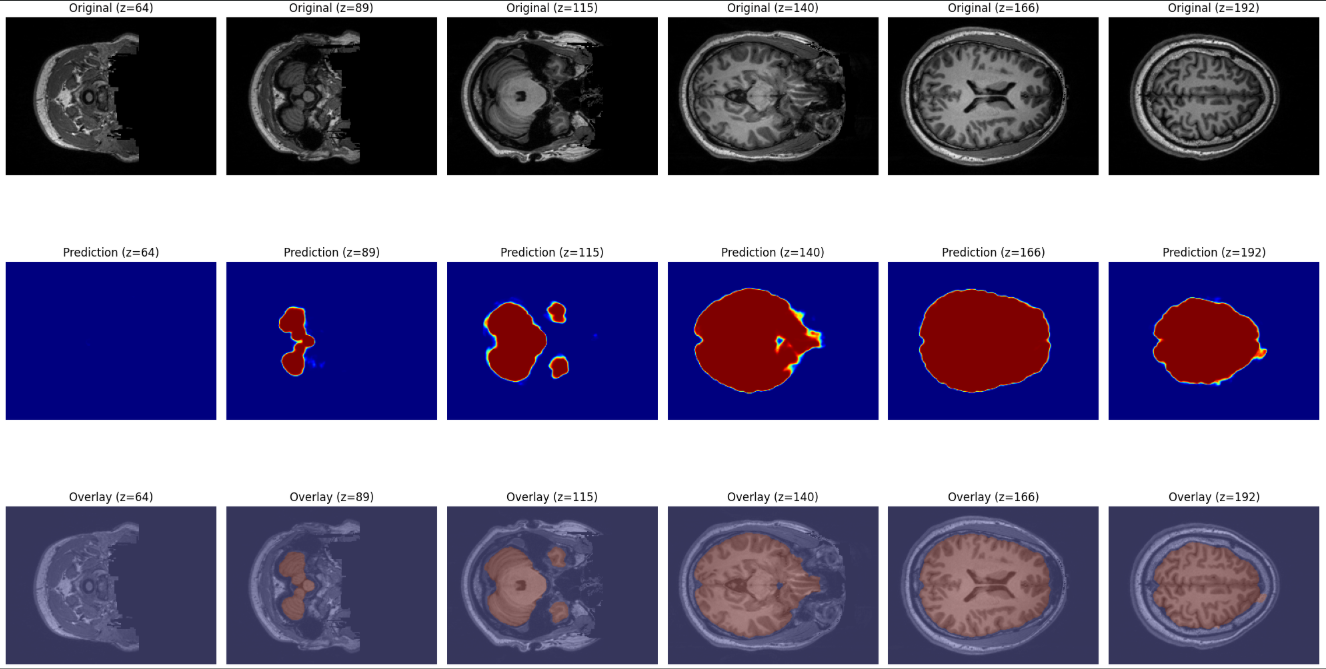
# ========== 単一スライスでの4種類表示 ==========
def visualize_results_four_types(original, prediction, binary_mask, slice_idx=None):
"""単一スライスで4種類の結果を表示"""
if slice_idx is None:
slice_idx = original.shape[2] // 2 # 中央のスライス
original_slice = original[:, :, slice_idx]
prediction_slice = prediction[:, :, slice_idx]
mask_slice = binary_mask[:, :, slice_idx]
skull_stripped = original_slice * (mask_slice > 0)
fig, axes = plt.subplots(1, 4, figsize=(20, 5))
# 1. 元画像
axes[0].imshow(original_slice, cmap='gray')
axes[0].set_title('Original Image', fontsize=12)
axes[0].axis('off')
# 2. 予測確率
axes[1].imshow(prediction_slice, cmap='hot', vmin=0, vmax=1)
axes[1].set_title('Prediction Probability', fontsize=12)
axes[1].axis('off')
# 3. バイナリマスク
axes[2].imshow(mask_slice, cmap='gray')
axes[2].set_title('Binary Mask', fontsize=12)
axes[2].axis('off')
# 4. Skull-stripped
axes[3].imshow(skull_stripped, cmap='gray')
axes[3].set_title('Skull-stripped Result', fontsize=12)
axes[3].axis('off')
plt.tight_layout()
plt.show()
# ========== 使用例 ==========
# 5. 結果の可視化(4種類表示)
print("結果を可視化中...")
visualize_results_four_types(test_volume, predicted_mask, binary_mask)
まとめ
本記事では、NFBS データセットを用いた深層学習ベースのスカルストリッピングの実装フローを紹介しました。データの取得・読み込み、可視化による確認、カスタムデータセットの構築、UNet による学習、推論、そして NIfTI 形式での保存まで、一連のパイプラインを構築する手順を解説しました。
スカルストリッピングは脳MRI画像解析における重要な前処理であり、深層学習を活用することで、従来手法に比べて高精度・高速な脳抽出が可能になります。本記事の内容をベースに、ご自身のデータや目的に合わせてパラメータやアーキテクチャを調整し、実践的な脳画像解析ワークフローを構築してみてください。