
【DICOM処理入門】PythonライブラリPydicomで読み込み・編集・匿名化・画像抽出まで実装しよう!

医療画像の標準フォーマットであるDICOMは、医療現場や研究で日々大量に扱われています。Pythonのライブラリ「Pydicom」を使えば、DICOMファイルの読み込み、編集、匿名化、さらには特定画像の抽出が簡単に行えます。 本記事では、Pydicomの基本から実践的な匿名化処理や画像抽出まで、初心者にもわかりやすく丁寧に解説します。
実行環境について(Google Colab を想定)
本記事のコードはGoogle Colab上での実行を想定しています。Colab を使うと、ローカル環境の構築なしでブラウザからすぐに実験できます。
①データの配置とアップロード
- 小規模なテストなら、Colab の左ペイン「ファイル」→「アップロード」でも可。
- 継続利用・大規模データは Google ドライブに格納し、上記マウント経由で参照するのが実務的です。
②Google ドライブのマウント
DICOM データを Google ドライブに置いておくと便利です。Colab からマウントして読み書きします。
from google.colab import drive
drive.mount('/content/drive')
# 作業ディレクトリ例
base_dir = '/content/drive/MyDrive/...' # 例:記事内のパスと揃えていますそもそもDICOMとは
DICOM(Digital Imaging and Communications in Medicine:医用画像および通信/ダイコム)は、医用画像および関連情報のフォーマットと交換方式を規定し、医用機器やシステム間の相互接続性を支える国際標準規格です。米国電気電子学会(NEMA)の承認のもと、医用画像および医療情報技術のユーザーとメーカーが共同で策定されました。
DICOMは以下の機器に幅広く実装されています:
- 放射線診断装置
- 循環器イメージング装置
- 放射線治療装置(X線、CT、MRI、超音波など)
- 眼科・歯科などの各種医療装置
世界中で数十万台の医用画像機器に導入され、臨床現場では実質的に数十億枚のDICOM画像が日々活用されています。
①Pydicomをインストールする
PydicomはDICOMファイルを扱うための純粋なPythonパッケージです。DICOMデータを「Pythonらしい」簡潔な方法で読み込み、修正、書き込みすることができます。
純粋なPython製のため、Pythonが動作するあらゆる環境で他の依存関係なしに実行可能ですが、ピクセルデータを扱う場合はNumPyを併せてインストールすることを推奨します。
pip install pydicomCollecting pydicom
Downloading pydicom-3.0.1-py3-none-any.whl.metadata (9.4 kB)
Downloading pydicom-3.0.1-py3-none-any.whl (2.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.4/2.4 MB 19.5 MB/s eta 0:00:00
Installing collected packages: pydicom
Successfully installed pydicom-3.0.1参考リンク
②データの読み込み・バイト列の確認
DICOMのピクセルデータは「生のバイト列」として格納されています。Pydicomで読み込み、バイト数や先頭のバイトを確認して中身を把握します。
from pydicom import dcmread #DICOM 読み込み用
from pydicom.data import get_testdata_file #テストデータ取得用ユーティリティ
path = get_testdata_file("CT_small.dcm") #パスを指定する
ds = dcmread(path) #データ読み込み
type(ds.PixelData) #圧縮済みバイト列そのままを返す
len(ds.PixelData) #バイト数を取得し、画像サイズとの対応を検証する
ds.PixelData[:2] #バイト列の先頭数バイトを切り出して内容を確認する>>> type(ds.PixelData)
<class 'bytes'>
>>> len(ds.PixelData)
32768
>>> ds.PixelData[:2]
b'\xaf\x00'このようにして、ピクセルデータが「ただの黒箱のバイト列」ではなく、自分の想定どおりのサイズ・構造をもった生データであることを確認した上で、ds.pixel_arrayによる展開・変形処理に進みます。
dcmread()は pydicom ライブラリの関数で、主に以下の引数があります:
| 引数名 | 型 | 説明 |
|---|---|---|
| fp | str / Path / file-like | 読み込む DICOM ファイルのパス(必須)。例: "path/to/file.dcm" |
| defer_size | int または str | 指定サイズ以上のバイナリデータ(Pixel Dataなど)を遅延読み込みする。メモリ節約に有効。例: "512 KB" |
| stop_before_pixels | bool | True にすると Pixel Data を読み込まずに終了する(ヘッダだけ読む場合に便利) |
| force | bool | True にすると DICOM 規格に完全準拠していないファイルでも強制的に読み込む |
| specific_tags | list[str] または list[pydicom.tag.Tag] | 指定したタグだけを読み込む(高速化・メモリ節約目的) |
| config | dict | 読み込み時の設定オプション(rare case向け、通常は不要) |
よく使うパターン:
# バイト列の確認
from pydicom import dcmread
from pydicom.data import get_testdata_file
path = get_testdata_file("CT_small.dcm")
ds = dcmread(path)
type(ds.PixelData)
len(ds.PixelData)
ds.PixelData[:2]
# 通常読み込み
ds = dcmread("image.dcm")
# Pixel Data を読み込まない(ヘッダ解析のみ)
ds = dcmread("image.dcm", stop_before_pixels=True)
# 大きい Pixel Data を遅延読み込み
ds = dcmread("image.dcm", defer_size="512 KB")
# 非準拠 DICOM を強制読み込み
ds = dcmread("broken_file.dcm", force=True)
# 特定タグだけ読み込む
from pydicom.tag import Tag
ds = dcmread("image.dcm", specific_tags=[Tag(0x0010, 0x0010)]) # 患者名だけ③DICOMヘッダーの内容の確認
患者情報、検査情報、画像情報など、多数の属性がDICOMファイルに含まれています。Pydicomでこれらのタグを参照し、どんな情報が入っているか把握しましょう。
dsDataset.file_meta -------------------------------
(0002,0000) File Meta Information Group Length UL: 192
(0002,0001) File Meta Information Version OB: b'\x00\x01'
(0002,0002) Media Storage SOP Class UID UI: CT Image Storage
(0002,0010) Transfer Syntax UID UI: Explicit VR Little Endian
(0002,0012) Implementation Class UID UI: 1.3.6.1.4.1.5962.2
(0002,0013) Implementation Version Name SH: 'DCTOOL100'
(0002,0016) Source Application Entity Title AE: 'CLUNIE1'
-------------------------------------------------
(0008,0005) Specific Character Set CS: 'ISO_IR 100'
(0008,0008) Image Type CS: ['ORIGINAL', 'PRIMARY', 'AXIAL']
(0008,0012) Instance Creation Date DA: '20040119'
(0008,0013) Instance Creation Time TM: '072731'
(0008,0014) Instance Creator UID UI: 1.3.6.1.4.1.5962.3
(0008,0016) SOP Class UID UI: CT Image Storage
(0008,0020) Study Date DA: '20040119'
(0008,0021) Series Date DA: '19970430'
(0008,0022) Acquisition Date DA: '19970430'
(0008,0023) Content Date DA: '19970430'
(0008,0030) Study Time TM: '072730'
(0008,0031) Series Time TM: '112749'
(0008,0032) Acquisition Time TM: '112936'
(0008,0033) Content Time TM: '113008'
(0008,0050) Accession Number SH: ''
(0008,0060) Modality CS: 'CT'
......
......
......よく使う主要フィールド:
患者情報・検査情報(これらはすべて匿名化時に非常に関連するフィールドであり、後ほど詳しく説明します)
| 属性名 | DICOM タグ | 説明 |
|---|---|---|
| PatientID | (0010,0020) | 患者 ID |
| PatientName | (0010,0010) | 患者氏名 |
| PatientAge | (0010,1010) | 患者年齢 |
| PatientSex | (0010,0040) | 患者性別 |
| StudyInstanceUID | (0020,000D) | 検査(スタディ)の一意識別子 |
| SeriesInstanceUID | (0020,000E) | シリーズの一意識別子 |
| SOPInstanceUID | (0008,0018) | イメージ/フレームの一意識別子 |
| Modality | (0008,0060) | 撮影モダリティ(CT、MR、CR など) |
| StudyDate / StudyTime | (0008,0020)/(0008,0030) | 検査日/検査時刻 |
画像ジオメトリと位置情報
| 属性名 | DICOM タグ | 説明 |
|---|---|---|
| Rows / Columns | (0028,0010)/(0028,0011) | 画像の高さ(行数)/ 幅(列数) |
| PixelSpacing | (0028,0030) | ピクセル間隔([垂直, 水平]、単位: mm) |
| SliceThickness | (0018,0050) | スライス厚(単位: mm) |
| ImagePositionPatient | (0020,0032) | 患者座標系における左上角の3D座標 |
| ImageOrientationPatient | (0020,0037) | 患者座標系における行方向/列方向ベクトル |
ピクセルデータと強度
| 属性名 | DICOM タグ | 説明 |
|---|---|---|
| BitsAllocated | (0028,0100) | 各ピクセルに割り当てられたビット数 |
| BitsStored | (0028,0101) | 実際に有効なビット数 |
| HighBit | (0028,0102) | 有効ビット中の最高ビット位置 |
| PixelRepresentation | (0028,0103) | 0=符号なし整数、1=符号付き整数 |
| PhotometricInterpretation | (0028,0004) | 画素値の解釈方法(例: MONOCHROME2) |
| RescaleSlope / RescaleIntercept | (0028,1053)/(0028,1052) | HU 変換用のスロープ/オフセット(存在すれば適用) |
ウィンドウ表示
| 属性名 | DICOM タグ | 説明 |
|---|---|---|
| WindowCenter | (0028,1050) | ウィンドウ中心(リストの場合は平均値や最初の要素) |
| WindowWidth | (0028,1051) | ウィンドウ幅 |
ファイルメタ情報
| 属性名 | 参照場所 | 説明 |
|---|---|---|
| ds.file_meta.TransferSyntaxUID | ds.file_meta | 圧縮/エンディアン情報を含むトランスファー構文 |
| ds.file_meta.MediaStorageSOPClassUID | ds.file_meta | 保存先の SOP Class(CT Image Storage など) |
コードで各フィールドを確認する:
項目名で確認する
# 基本情報の確認
print(f"Patient ID : {ds.get('PatientID', 'Unknown')}")
print(f"Rows × Columns: {ds.Rows} × {ds.Columns}")
print(f"BitsAllocated : {ds.BitsAllocated}")
print(f"PixelRepresentation: {ds.PixelRepresentation}")
# 生のバイト長など
print(f"Raw PixelData length: {len(ds.PixelData)} bytes")タグで確認する
# タグをタプルで直接指定して値を取得
patient_id = ds[(0x0010, 0x0020)].value
rows = ds[(0x0028, 0x0010)].value
columns = ds[(0x0028, 0x0011)].value
bits_allocated = ds[(0x0028, 0x0100)].value
pixel_representation = ds[(0x0028, 0x0103)].value
raw_bytes = ds[(0x7FE0, 0x0010)].value
# 出力
print(f"Patient ID : {patient_id}")
print(f"Rows × Columns : {rows} × {columns}")
print(f"BitsAllocated : {bits_allocated}")
print(f"PixelRepresentation : {pixel_representation}")
print(f"Raw PixelData length : {len(raw_bytes)} bytes")Patient ID : 1CT1
Rows × Columns : 128 × 128
BitsAllocated : 16
PixelRepresentation : 1
Raw PixelData length : 32768 bytes④DICOM データの変更
Pydicomでは、DICOMデータの属性(タグ)をPythonオブジェクトのプロパティとして直接書き換えられます。修正した後は、save_asメソッドでファイルに保存可能です。匿名化やデータ修正の目的で属性を書き換えることは一般的に行われています。匿名化の具体例については後の章で詳しく説明します。
import os
# 1. 属性を変更
ds.PatientID = "12345678"
ds.PatientName = "Tanaka"
# 必要に応じて他のタグも同様に変更できます
# 2. 保存先ディレクトリの確認・作成
out_dir = "/content/drive/MyDrive/エム/output"
os.makedirs(out_dir, exist_ok=True)
# 3. 保存
out_path = os.path.join(out_dir, "dicom_updated.dcm")
ds.save_as(out_path, enforce_file_format=True)
print(f"Saved: {out_path}")(補充)匿名化に関わるDICOM UID
SOPInstanceUID、SeriesInstanceUID、StudyInstanceUIDはDICOMで使われる重要なUID(Unique Identifier)で、医用画像の階層構造を識別するために使われます。これらの違いと生成方法について詳しく解説します。
| UID名 | 意味・役割 | 位置づけ(階層構造) |
|---|---|---|
| StudyInstanceUID(スタディUID) | 研究(検査)単位を一意に識別するID。患者に対して行われる1回の検査や撮影全体を示す。例:胸部CT検査1回分の全データ。 | 最上位階層(検査レベル)。1つのStudyInstanceUIDの下に複数のSeriesInstanceUIDが存在する。 |
| SeriesInstanceUID(シリーズUID) | シリーズ単位を一意に識別するID。1つの検査(Study)内で、撮影条件や撮影方法が異なるまとまりを示す。例:胸部CT検査内の「造影CTシリーズ」や「非造影CTシリーズ」など。 | StudyInstanceUIDの下位に位置する階層。1つのSeriesInstanceUIDの下に複数のSOPInstanceUIDが存在する。 |
| SOPInstanceUID(SOPインスタンスUID) | 個々のDICOMオブジェクト(インスタンス)を一意に識別するID。実際の画像スライスやレポート、波形データなどの1つ1つのファイル単位。例:CTスライス1枚、MRIの1枚の画像。 | SeriesInstanceUIDの下位に位置。一番具体的な1つのオブジェクトを示す。 |
UIDを生成するタイミング:
| タイミング | UID生成の必要性 | 詳細説明 |
|---|---|---|
| 新規DICOMデータ作成時 | 必須 | 新しい検査や画像データを作成するとき。全てのUIDは固有のものに。 |
| データ匿名化時 | 必須 | 個人情報保護のため、既存UIDを新規UIDに置き換える必要がある。 |
| データ結合・移行時 | 必須 | 複数データセットを統合する際、UIDの重複防止のため新規UIDを発行する場合がある。 |
| 単に閲覧・解析する時 | 不要 | 既存DICOMを読み込み、UIDは変更せずそのまま扱う。 |
| 画像情報の軽微な編集時 | 基本不要 | 画像ピクセル以外のタグ変更など、UIDを変えず編集可能。 |
階層構造イメージ:
StudyInstanceUID(検査全体)
│
├── SeriesInstanceUID(撮影シリーズ)
│ ├── SOPInstanceUID(画像スライス1)
│ ├── SOPInstanceUID(画像スライス2)
│ └── ...
├── SeriesInstanceUID(別の撮影シリーズ)
│ └── SOPInstanceUID(画像スライス1)
└── ...UID生成の具体的な方法(Python)
- DICOM UIDは世界で唯一の識別子である必要があり、OID(数字の階層表現)形式をとる。
- 生成には、組織固有のルートOID+日時・乱数等を組み合わせて作成するのが一般的。
- 実装では、Pythonのpydicomのgenerate_uid()が推奨される。これでDICOM準拠のユニークUIDを安全に作成可能。
from pydicom.uid import generate_uid
# UID生成
study_uid = generate_uid() # StudyInstanceUID
series_uid = generate_uid() # SeriesInstanceUID
sop_uid = generate_uid() # SOPInstanceUID
print("StudyInstanceUID:", study_uid)
print("SeriesInstanceUID:", series_uid)
print("SOPInstanceUID:", sop_uid)StudyInstanceUID: 1.2.826.0.1.3680043.8.498.31235814198597222070139176713832568668
SeriesInstanceUID: 1.2.826.0.1.3680043.8.498.27442425900934542686965838853309741812
SOPInstanceUID: 1.2.826.0.1.3680043.8.498.69477644020097174792921290712708516633実務上のポイント
- UIDの変更は慎重に:既存UIDの変更は原則禁止。患者の検査履歴や画像の一貫性保持のため。
- 新規データ作成時は必ずUIDを生成:ソフトウェアで新しい検査や画像を作る場合は必須。
- 匿名化時は元UIDを必ず差し替える:個人特定を防ぐために必要。
- UIDの階層関係を守ることが重要:Study→Series→SOPの階層構造に沿った管理が不可欠。
⑤ NumPy配列への変換
DICOM画像のピクセルデータはds.pixel_arrayを使うと簡単にNumPy配列として取得できます。これにより、NumPyやOpenCV、scikit-image、機械学習ライブラリなどと連携しやすくなり、画像処理が可能になります。
import numpy as np
arr = ds.pixel_array
arr.shape
arr>>> arr.shape
(128, 128)
>>> arr
array([[175, 180, 166, ..., 203, 207, 216],
[186, 183, 157, ..., 181, 190, 239],
[184, 180, 171, ..., 152, 164, 235],
...,
[906, 910, 923, ..., 922, 929, 927],
[914, 954, 938, ..., 942, 925, 905],
[959, 955, 916, ..., 911, 904, 909]], dtype=int16)⑥DICOM データの可視化
NumPy配列に変換したDICOM画像は、Matplotlibを使って簡単に表示できます。PydicomでDICOMファイルを読み込み、NumPy配列に変換し、Matplotlibで可視化する流れは、医用画像解析の基礎的な作業として非常に重要です。
以下のコードはグレースケール画像として表示する例です:
import matplotlib.pyplot as plt
plt.imshow(arr, cmap="gray")
plt.show()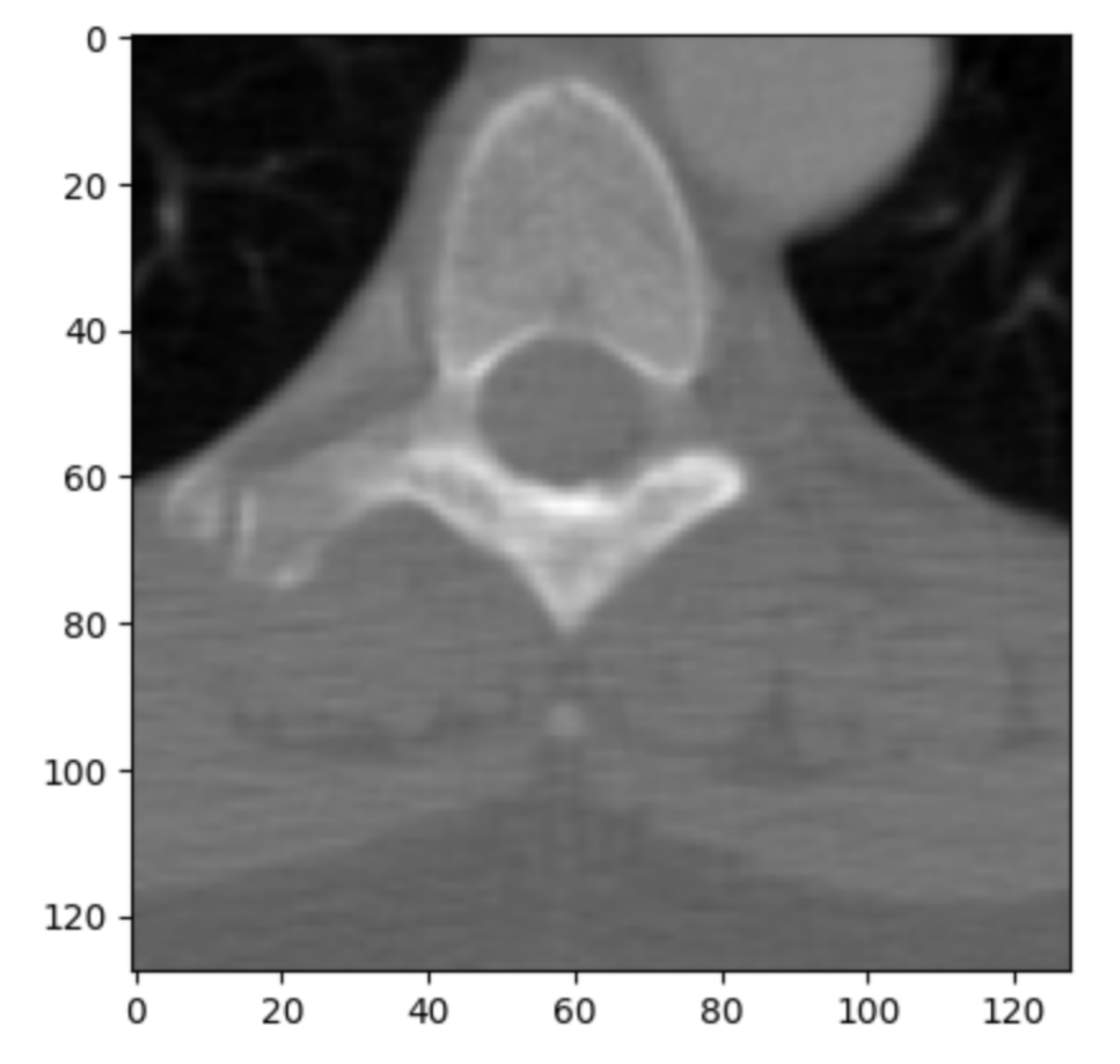
匿名化処理:患者プライバシー保護の必須ステップ
DICOMファイルの匿名化は、患者のプライバシー保護のために不可欠な処理です。個人情報を特定できるタグの値を削除・置換し、さらにメーカー固有のプライベートタグを除去することで、安全なデータ共有や解析を実現します。
主な匿名化手法
| 手法名 | 内容 | 効果・役割 |
|---|---|---|
| 個別タグの値の書き換え・削除 | PatientName、PatientID、PatientBirthDate などの値を置換・空文字にする | 個人が特定できる重要情報を確実に匿名化 |
| remove_private_tags() | メーカーや病院固有のプライベートタグをDICOMファイルから一括削除 | 見落としがちな固有情報をまとめて除去し、匿名化の網羅性を高める |
| 標準タグの追加匿名化 | AcquisitionDate、InstitutionName なども匿名化対象に含める | 個人識別につながる可能性のある情報を漏れなく匿名化 |
(補充)タグの説明(詳しいまとめは前節【よく使う主要フィールド】をご参照ください。)
| DICOMタグ | 匿名化後の値 | 説明 |
|---|---|---|
| ds.PatientName | "anonymous" | 患者名を示すタグ。実際の患者の名前を匿名化して「anonymous」などの文字列に置き換えます。 |
| ds.PatientID | "000000" | 患者ID(病院内で患者を識別する番号)を示すタグ。個人が特定されないように「000000」などの無意味な番号に置き換えます。 |
| ds.PatientBirthDate | ""(空文字) | 患者の生年月日を示すタグ。生年月日も個人情報なので、空文字にして削除します。 |
| ds.AcquisitionDate | ""(空文字) | 画像の取得日(撮影日)を示すタグ。撮影日が分かると個人特定につながる恐れがあるため、空文字にして隠します。 |
| ds.InstitutionName | ""(空文字) | 医療機関や検査施設の名称を示すタグ。施設名を削除して、どこの病院で撮影したかを分からなくします。 |
匿名化の実装例(Python)
ここでは弊社が保有しているMRIデータを用いて説明します。ご自身でデータをご用意ください。
【Pydicomをインストールする】で説明されているように、データを読み込み内容を確認しておいてください。
import os
import pydicom
def anonymize_dicom_file(input_path, output_path):
ds = pydicom.dcmread(input_path)
ds.remove_private_tags()
ds.PatientName = "anonymous"
ds.PatientID = "000000"
ds.PatientBirthDate = ""
ds.AcquisitionDate = ""
ds.InstitutionName = ""
# 必要に応じて他のタグも匿名化
os.makedirs(os.path.dirname(output_path), exist_ok=True)
ds.save_as(output_path)
def anonymize_dicom_dir(input_dir, output_dir):
for root, dirs, files in os.walk(input_dir):
for file in files:
input_path = os.path.join(root, file)
relative_path = os.path.relpath(input_path, input_dir)
output_path = os.path.join(output_dir, relative_path)
anonymize_dicom_file(input_path, output_path)
print(f"匿名化: {input_path} -> {output_path}")
# 使用例
input_folder = "入力ディレクトリのパス"
output_folder = "出力ディレクトリのパス"
anonymize_dicom_dir(input_folder, output_folder)匿名化: 入力ディレクトリのパス/ファイル名 -> 出力ディレクトリのパス/ファイル名
匿名化: 入力ディレクトリのパス/ファイル名 -> 出力ディレクトリのパス/ファイル名
匿名化: 入力ディレクトリのパス/ファイル名 -> 出力ディレクトリのパス/ファイル名
匿名化: 入力ディレクトリのパス/ファイル名 -> 出力ディレクトリのパス/ファイル名
匿名化: 入力ディレクトリのパス/ファイル名 -> 出力ディレクトリのパス/ファイル名
匿名化: 入力ディレクトリのパス/ファイル名 -> 出力ディレクトリのパス/ファイル名
匿名化: 入力ディレクトリのパス/ファイル名 -> 出力ディレクトリのパス/ファイル名
匿名化: 入力ディレクトリのパス/ファイル名 -> 出力ディレクトリのパス/ファイル名
......こうすると、匿名化したファイルは「出力ディレクトリのパス」フォルダに保存されます。
注意点
- 完全な匿名化は難しく、DICOM標準の匿名化プロファイルに従うことが望ましい。
- 実際の運用では、どのタグを匿名化対象にするかを明確に決めておくことが重要。
- プライベートタグを削除しても個人特定につながる情報が残ることがあるため、追加のチェックが必要な場合もある。
DICOMから特定の画像を抽出するやり方
検査データには多数の撮影シリーズが含まれます。例えば「FLAIR」というキーワードを含むシリーズだけを抽出・コピーして整理したい場合に便利なスクリプト例です。
準備:ご自身で対象のDICOMデータをご用意ください。Python環境とpydicomライブラリがインストールされていることを確認してください。
実装のポイント
| 処理内容 | 説明 |
|---|---|
| フォルダ内のDICOMファイル走査 | 指定フォルダ以下の全てのファイルを探索し、DICOMファイルを特定する。 |
| SeriesDescriptionの確認 | 各DICOMファイルのSeriesDescriptionタグを読み込み、「FLAIR」という文字列を含むか判定。 |
| 該当ファイルの抽出 | 「FLAIR」が含まれるDICOMファイルのみを選択。 |
| フォルダ構造を保持したコピー | 元フォルダからの相対パスを保ちながら、別の指定フォルダにファイルをコピー。 |
import os
import shutil
import pydicom
def copy_flair_files(input_dir, output_dir, target_keyword="FLAIR"):
for root, dirs, files in os.walk(input_dir):
for file in files:
file_path = os.path.join(root, file)
try:
ds = pydicom.dcmread(file_path, stop_before_pixels=True)
if hasattr(ds, 'SeriesDescription') and target_keyword.upper() in ds.SeriesDescription.upper():
relative_path = os.path.relpath(file_path, input_dir)
dest_path = os.path.join(output_dir, relative_path)
os.makedirs(os.path.dirname(dest_path), exist_ok=True)
shutil.copy2(file_path, dest_path)
print(f"複製: {file_path} -> {dest_path}")
except Exception:
continue
# 使用例
input_folder = "入力ディレクトリのパス"
output_folder = "出力ディレクトリのパス"
copy_flair_files(input_folder, output_folder)複製: 入力ディレクトリのパス/ファイル名 -> 出力ディレクトリのパス/ファイル名
複製: 入力ディレクトリのパス/ファイル名 -> 出力ディレクトリのパス/ファイル名
複製: 入力ディレクトリのパス/ファイル名 -> 出力ディレクトリのパス/ファイル名
複製: 入力ディレクトリのパス/ファイル名 -> 出力ディレクトリのパス/ファイル名
...まとめ
Pydicomを使うことで、DICOMファイルの読み込み、編集、匿名化、特定画像の抽出、UID生成まで幅広い医療画像処理に対応可能です。
患者プライバシーを守るための匿名化は必須のステップですので、今回紹介した手法を参考に、安全かつ効率的な医療画像処理を目指しましょう。