
NiBabel徹底入門!Pythonで医療画像処理を実践しよう
医療画像処理は、現代の医療診断や研究において非常に重要な役割を果たしています。MRI、CT、PETなどの画像診断技術の発展により、膨大な量の医療画像データが日々生成されています。これらのデータを効率的に処理・分析するためには、専門的なツールが必要です。 Pythonは、その豊富なライブラリと使いやすさから、医療画像処理の分野でも広く採用されています。特に「NiBabel」は、神経画像データの読み込み・操作・保存を行うための強力なPythonライブラリであり、多くの研究者や開発者に利用されています。 本記事では、NiBabelの基本的な使い方から応用例まで、実践的なPythonコード例とともに解説します。Google Colaboratoryを使った環境構築から始め、実際の医療画像データを用いた処理方法を詳しく説明します。
NiBabelとは
NiBabel(Neuroimaging in Python: NIFTI, ANALYZE, GIFTI, CIFTI, MINC, MGH/MGZ, ECAT, DICOM, BRIK/HEAD, AFNI, NRRD)は、神経画像データの読み込み・操作・書き込みを行うためのPythonパッケージです。主に以下のような医療画像フォーマットをサポートしています:
- NIfTI-1 (.nii, .nii.gz)
- ANALYZE (.hdr/.img)
- MGH/MGZ (.mgh, .mgz)
- その他多数
NiBabelは、Nipy(Neuroimaging in Python)プロジェクトの一部として開発されており、医療画像処理のための他のPythonツール(例:Nilearn、Dipy)と組み合わせて使用されることが多いです。
参考リンク
Google Colaboratoryでの環境構築
Google Colaboratory(略してColab)は、ブラウザ上でPythonコードを実行できるクラウドサービスです。GPUを無料で利用できる点や、環境構築が容易な点から、医療画像処理のような計算負荷の高いタスクに適しています。
Google Colabの主な特徴と利点は以下の通りです:
- 無料のGPU/TPUアクセス:深層学習や大規模データ処理などの計算負荷の高いタスクを、無料でGPUやTPUを使って高速に実行できます。
- 環境構築が不要:Pythonや多くの科学計算・機械学習ライブラリが事前にインストールされているため、すぐにコーディングを始められます。
- Jupyterノートブック互換:コードセルとテキストセルを組み合わせた形式で、コードの実行結果とドキュメントを一体化して管理できます。
- Google Driveとの連携:データの保存や共有が簡単に行えます。
- ウェブブラウザだけで利用可能:特別なソフトウェアのインストールが不要です。
まずは、ColabでNiBabelを使用するための環境を整えましょう。ライブラリのインポートから始めます。
# NiBabelのインストール
# ローカル環境で実行している方はライブラリをインストールしてください。
# !pip install nibabel matplotlib
# 必要なライブラリのインポート
import nibabel as nib
from nibabel import processing
import numpy as np
import matplotlib.pyplot as plt
import osサンプルデータの取得
実際に医療画像を処理するために、サンプルデータを取得しましょう。ここでは、GitHubリポジトリから脳MRIのサンプルデータをダウンロードして使用します。
# GitHubからサンプルの脳MRIデータをダウンロード
!git clone https://github.com/corporate-m/TestBrain.git
print("サンプルデータのダウンロードが完了しました。")
# ダウンロードしたNIfTIファイルのパス
mri_file_path = '/content/TestBrain/T1_3D_MPRAGE.nii.gz'Cloning into 'TestBrain'...
remote: Enumerating objects: 6, done.
remote: Counting objects: 100% (6/6), done.
remote: Compressing objects: 100% (4/4), done.
remote: Total 6 (delta 0), reused 0 (delta 0), pack-reused 0 (from 0)
Receiving objects: 100% (6/6), 11.00 MiB | 5.50 MiB/s, done.
サンプルデータのダウンロードが完了しました。医療画像データの読み込みと基本情報の表示
NiBabelを使用して医療画像(NIfTIファイル)を読み込む際、まず最初に使うのが load 関数です。この関数は、NIfTIファイル(.niiや.nii.gzなど)を読み込み、画像データ本体と空間情報・メタデータを含む「画像オブジェクト」を生成します。
このオブジェクトから、画像データ本体(NumPy配列として取得可能)、アフィン変換行列(affine)、ヘッダー情報(header)など、医療画像解析に必要な情報を簡単に取り出すことができます。
load関数は、指定したパスのNIfTIファイルを読み込み、NiBabelの画像オブジェクト(例:Nifti1Image)を返します。このオブジェクトは、画像データ本体だけでなく、空間情報やメタデータも保持しているため、医療画像処理のさまざまな場面で活用できます。
affine属性は、画像のボクセル座標(配列のインデックス)を実空間(mm単位など)に変換するための4×4行列です。この行列により、画像データがどの位置・向き・スケールで空間上に配置されているかを正確に記述できます。
用途例
- 複数の画像を空間的に重ね合わせる(コアジストレーション)
- 実際の解剖学的位置と画像データを対応付ける
行列の構造
- 上3行3列:回転・スケーリング・シアー(変形)成分
- 最終列(上3行):平行移動(オフセット)成分
- 最終行:常に [0, 0, 0, 1]
header属性は、画像データに付随するメタデータ(付加情報)を格納したオブジェクトです。NIfTI形式では、ヘッダーに画像の次元数、ボクセルサイズ、データ型、スキャン条件など多くの情報が含まれています。
主なフィールド例
- dim:画像の次元情報(例:3次元画像なら[3, x, y, z, ...])
- pixdim:各次元のボクセルサイズ(mm単位)
- datatype:データ型(int16, float32など)
これらを利用することで、画像の読み込みから空間情報の取得、メタデータの参照まで一貫して行えます。affineとheaderの重要性は超入門編だけでは扱いきれないため、別の機会に解説を行う予定です。
# NIfTIファイルの読み込み
img = nib.load(mri_file_path)
# 画像オブジェクトの基本情報を表示
print(f"画像の形式: {img.get_filename()}")
print(f"画像の形状: {img.shape}")
print(f"データ型: {img.get_data_dtype()}")
print(f"アフィン変換行列:\n{img.affine}")
print(f"ヘッダー情報の概要:\n{img.header}")画像の形式: /content/TestBrain/T1_3D_MPRAGE.nii.gz
画像の形状: (176, 256, 256)
データ型: int16
アフィン変換行列:
[[ 9.95444715e-01 -1.37224142e-02 9.43629071e-02 -9.98668747e+01]
[ 1.15260696e-02 9.99650717e-01 2.37814859e-02 -8.72018280e+01]
[-9.46564227e-02 -2.25854889e-02 9.95253801e-01 -1.34625244e+02]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 1.00000000e+00]]
ヘッダー情報の概要:
object, endian='<'
sizeof_hdr : 348
data_type : np.bytes_(b'')
db_name : np.bytes_(b'')
extents : 0
session_error : 0
regular : np.bytes_(b'r')
dim_info : 54
dim : [ 3 176 256 256 1 1 1 1]
intent_p1 : 0.0
intent_p2 : 0.0
intent_p3 : 0.0
intent_code : none
datatype : int16
bitpix : 16
slice_start : 0
pixdim : [1. 1. 1. 1. 1.8 0. 0. 0. ]
vox_offset : 0.0
scl_slope : nan
scl_inter : nan
slice_end : 0
slice_code : unknown
xyzt_units : 10
cal_max : 0.0
cal_min : 0.0
slice_duration : 0.0
toffset : 0.0
glmax : 0
glmin : 0
descrip : np.bytes_(b'TE=2.1;Time=122833.990;phase=1')
aux_file : np.bytes_(b'')
qform_code : scanner
sform_code : scanner
quatern_b : -0.0116057545
quatern_c : 0.047311917
quatern_d : 0.0063197464
qoffset_x : -99.866875
qoffset_y : -87.20183
qoffset_z : -134.62524
srow_x : [ 9.9544472e-01 -1.3722414e-02 9.4362907e-02 -9.9866875e+01]
srow_y : [ 1.1526070e-02 9.9965072e-01 2.3781486e-02 -8.7201828e+01]
srow_z : [-9.4656423e-02 -2.2585489e-02 9.9525380e-01 -1.3462524e+02]
intent_name : np.bytes_(b'')
magic : np.bytes_(b'n+1')よく使われる便利な関数: as_closest_canonical と squeeze_image
医療画像処理では、画像の向きを標準化したり、不要な次元を削除したりすることがよくあります。NiBabelには、これらの操作を簡単に行うための便利な関数が用意されています。
as_closest_canonical関数は画像データを「標準的な」向き(RAS: Right-Anterior-Superior)に変換し、squeeze_image関数はサイズが1の余分な次元を削除します。
画像データの取得と表示
NiBabelで読み込んだ画像データは、NumPy配列として取得できます。これにより、様々な数値処理や可視化が可能になります。NumPy配列にするにはget_fdata属性を用います。
# 画像データをNumPy配列として取得
data = img.get_fdata()
print(f"データの形状: {data.shape}")
print(f"最小値: {data.min()}, 最大値: {data.max()}, 平均値: {data.mean()}")
# 3次元データ(x, y, z)の中央のスライスを取得
x, y, z = data.shape
slice_x = data[x//2, :, :] # 矢状断面(Sagittal)
slice_y = data[:, y//2, :] # 冠状断面(Coronal)
slice_z = data[:, :, z//2] # 軸位断面(Axial)
# Matplotlibを使用して3つの断面を同時に表示
plt.figure(figsize=(18, 6))
plt.subplot(131)
plt.imshow(slice_x.T, cmap='gray', origin='lower')
plt.title('Sagittal')
plt.subplot(132)
plt.imshow(slice_y.T, cmap='gray', origin='lower')
plt.title('Coronal')
plt.subplot(133)
plt.imshow(slice_z.T, cmap='gray', origin='lower')
plt.title('Axial')
plt.tight_layout()
plt.show()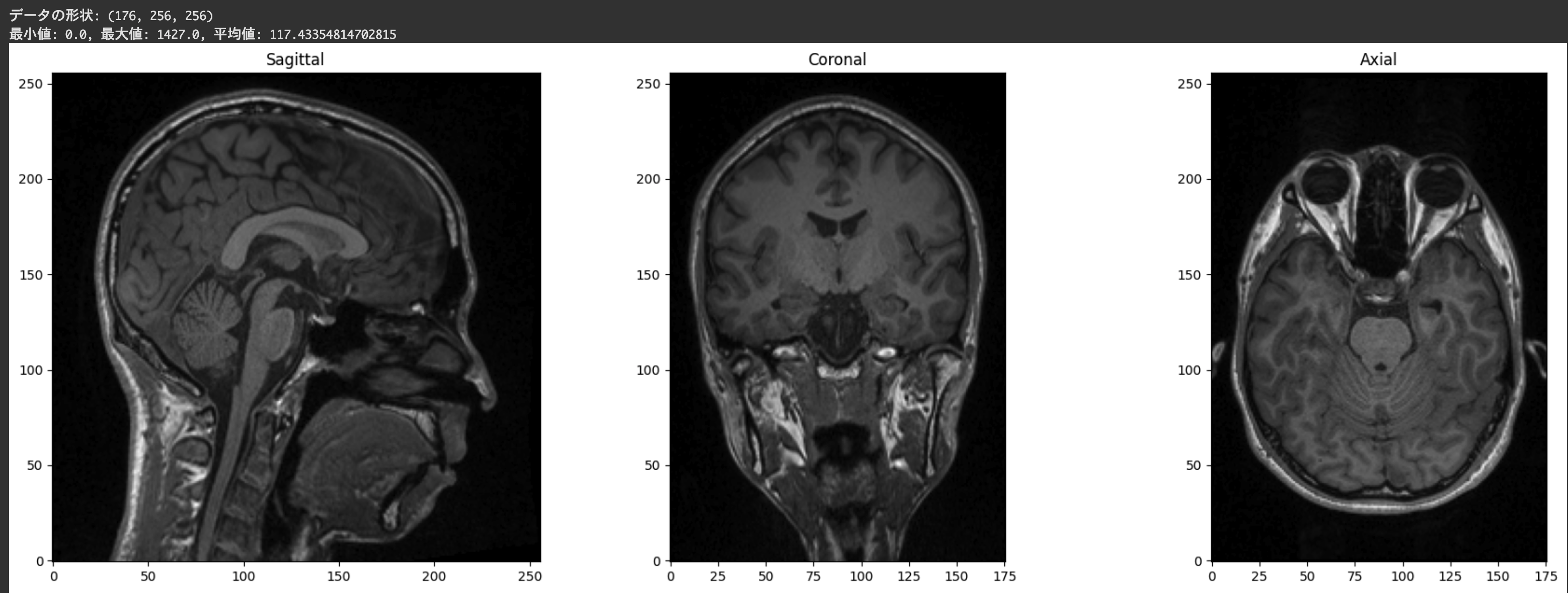
conform関数の詳細
conform関数は、MRI画像を標準的な形状とボクセルサイズに変換するための強力なツールです。conform関数は、引数で細かく指定しない場合、デフォルトで1mm等方性ボクセルサイズの256×256×256の3D画像に変換します。これにより、異なるスキャナーや撮像シーケンスから取得した画像を均一な形式に揃えることができます。
conform(from_img, out_shape=(256, 256, 256), voxel_size=(1.0, 1.0, 1.0), order=3, cval=0.0, orientation='RAS', out_class=None)主な引数:
- from_img:変換したい画像オブジェクト
- out_shape:出力画像の形状(デフォルト: (256, 256, 256))
- voxel_size:出力画像のボクセルサイズ(mm単位)(デフォルト: (1.0, 1.0, 1.0))
- order:スプライン補間の次数(デフォルト: 3)。0は最近傍補間、1は線形補間、3は3次スプライン補間(より滑らか)
- cval:境界外の値(デフォルト: 0.0)
- orientation:出力画像の向き(デフォルト: 'RAS')
conform関数は、さまざまな引数を組み合わせることで、用途に応じた柔軟な画像変換が可能です。
import matplotlib.pyplot as plt
# 例1: デフォルト設定(1mm等方性・256x256x256・3次スプライン補間)
img_conformed_default = processing.conform(img, voxel_size=(1.0, 1.0, 1.0))
print(f"デフォルト変換後の形状: {img_conformed_default.shape}")
# 例2: 2mm等方性ボクセル・形状(128,128,128)・線形補間
img_conformed_2mm = processing.conform(
img,
out_shape=(128, 128, 128),
voxel_size=(2.0, 2.0, 2.0),
order=1 # 線形補間
)
print(f"2mm等方性・128x128x128変換後の形状: {img_conformed_2mm.shape}")
# 例3: 1mm等方性・256x256x256・最近傍補間・境界外値を-1000に設定
img_conformed_axial = processing.conform(
img,
out_shape=(256, 256, 256),
voxel_size=(1.0, 1.0, 1.0),
order=0, # 最近傍補間
cval=-1000.0 # 境界外値
)
print(f"最近傍補間・境界外値-1000変換後の形状: {img_conformed_axial.shape}")
# 画像の中央スライスを表示して変化を比較
def show_center_slice(img_obj, title):
data = img_obj.get_fdata()
center = tuple(s // 2 for s in data.shape)
# 軸位断面(z軸中央スライス)を表示
plt.imshow(data[:, :, center[2]].T, cmap='gray', origin='lower')
plt.title(title)
plt.figure(figsize=(15, 4))
plt.subplot(1, 3, 1)
show_center_slice(img_conformed_default, "Default (1mm/256)")
plt.subplot(1, 3, 2)
show_center_slice(img_conformed_2mm, "2mm Isotropic (128)")
plt.subplot(1, 3, 3)
show_center_slice(img_conformed_axial, "Nearest/Boundary -1000")
plt.tight_layout()
plt.show().png)
NumPy配列からNiBabel形式への再変換と保存
画像データをNumPy配列として処理した後、再びNiBabel形式(Nifti1Image)に戻して保存することで、他のツールや解析パイプラインでも再利用できるようになります。ここでは、NumPy配列からNIfTIファイルとして保存する一連の流れと、保存時の各引数について詳しく解説します。
NumPy配列として取得 img.get_fdata()で画像データをNumPy配列として取得します。これにより、NumPyの各種演算や画像処理が自由に行えます。
NiBabel形式に再変換 nib.Nifti1Image(data, affine, header)の各引数は以下の通りです。
- data:保存したい画像データ(NumPy配列)。形状やデータ型はNIfTI仕様に準拠している必要があります。
- affine:4×4のアフィン変換行列。画像の空間的な位置や向きを定義します。通常は元画像のimg.affineをそのまま使います。
- header:NIfTIヘッダー情報。データ型やボクセルサイズ、スライス数などのメタデータを含みます。元画像のimg.headerを流用することで、空間情報や撮像条件を保持できます。
ファイルとして保存 nib.save(画像オブジェクト, ファイル名, overwrite=False)でNIfTIファイルとして保存します。
- 画像オブジェクト:Nifti1ImageなどNiBabelの画像クラスのインスタンス。
- ファイル名:保存先のファイル名。拡張子が.nii.gzの場合は自動的にgzip圧縮されます。.niiの場合は非圧縮で保存されます。
- overwrite(オプション):既存ファイルがある場合に上書きするかどうかを指定します。デフォルトはFalseで、同名ファイルが存在するとエラーになります。上書きしたい場合はoverwrite=Trueを指定してください(NiBabel 5.1以降で利用可能)。
import nibabel as nib
# 1. 画像データをNumPy配列として取得
data = img.get_fdata()
# 2. NiBabel形式(Nifti1Image)に再変換
img_new = nib.Nifti1Image(data, img.affine, img.header)
# 3. ファイルとして保存
nib.save(img_new, 'output_image.nii.gz')
print("画像をoutput_image.nii.gzとして保存しました。")画像をoutput_image.nii.gzとして保存しました。まとめ
本記事では、NiBabelを用いた医療画像(特にMRIデータ)の基本的な取り扱い方法から、実践的な前処理・変換・保存までの一連の流れを解説しました。NiBabelは、PythonのNumPy配列と密接に連携できるため、画像データの数値処理や可視化、さらには機械学習や統計解析への応用も容易です。
特に、conform関数を活用することで、異なるスキャナーや撮像条件で取得された画像を統一フォーマットに揃え、解析の信頼性や再現性を高めることができます。また、NumPy配列として処理した画像を再びNIfTI形式で保存することで、他の解析ツールやワークフローとの連携もスムーズに行えます。
医療画像処理の現場では、データの標準化や再利用性がますます重要になっています。NiBabelを活用することで、効率的かつ柔軟な画像解析パイプラインを構築し、研究や臨床現場でのデータ活用の幅を広げていきましょう。
次のアクション
- NiBabelの公式ドキュメントやAPIリファレンスを参照し、より高度な機能や他フォーマットの取り扱いにも挑戦してみましょう。
- NilearnやDipyなど、NiBabelと連携可能な他のPythonライブラリも活用し、画像解析の自動化や可視化をさらに発展させてください。
- 本記事のサンプルコードを自身のデータセットに適用し、実際の研究や業務での活用を進めてみましょう。